https://zhuanlan.zhihu.com/p/646885743
Stable Diffision最新模型SDXL 1.0使用全教程
SDXL 1.0 的新特性
 7月26日Stability AI开源了大家期待已久的全球最强文生图模型SDXL 1.0。
SDXL 1.0具有以下新特性: - 更好的成像质量:SDXL能够以几乎任何艺术风格生成高质量的图像,SDXL 1.0比SD v1.5和SD v2.1(甚至比SDXL 0.9)都有巨大的提升!盲测者评估图像在各种风格、概念和类别中的整体质量和美学都是最好的。
- 更多艺术风格:SDXL v1.0比其前身能够实现更多的风格,并且对每种风格都“知道”得更多。您可以尝试比以前更多的艺术家名称和美学。SDXL 1.0特别适合生动、准确的颜色,比其前身具有更好的对比度、光照和阴影,质量可与Midjourney的最新版本相媲美。
- 更智能、更简单的语言:SDXL只需要几个词就能创建复杂、详细、美观的图像。用户不再需要调用“杰作”等限定词来获得高质量图像。此外,SDXL能够理解诸如“红场”(一个著名的地方)与“红色正方形”(一个形状)之间的概念差异。
- 更高的分辨率:SDXL 1.0的基础分辨率为1024 x 1024,比其前身产生了更好的图像细节,同时SDXL 1.0处理宽高比效果更好。
- 最大的开放图像模型:SDXL 1.0拥有任何开源文生图模型中最大的参数数量之一,它建立在一个创新的新架构上,由一个3.5B参数基础模型和一个6.6B参数精炼器组成。完整模型由一个专家混合管道组成,用于潜在扩散:
- 微调和高级控制:使用SDXL 1.0,微调模型以适应自定义数据比以往更容易。可以使用更少的数据整理来生成自定义LoRAs或检查点。Stability AI团队正在构建T2I/ControlNet专门针对SDXL构建下一代的特定任务结构、样式和组成控制。
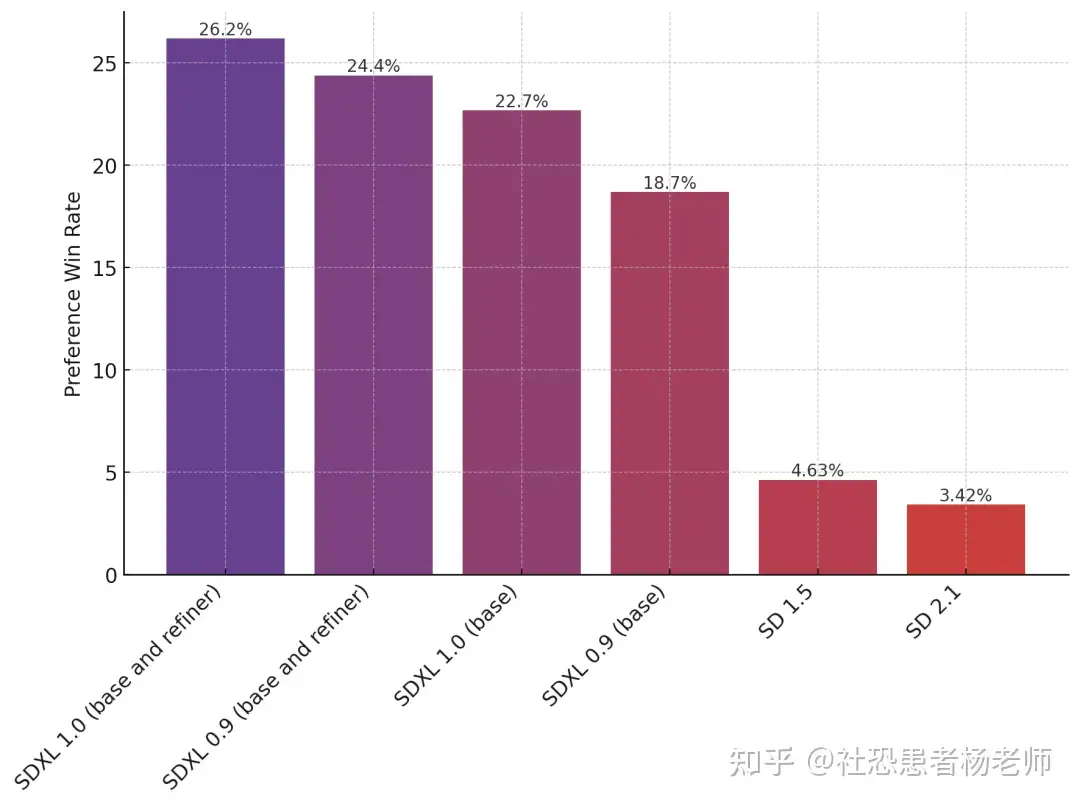
 Stability AI 将 SDXL 1.0 与各种模型进行了对比测试,即在Discord上进行了这几代Stable Diffusion模型的偏好测试,可以看到:人们更喜欢由 SDXL 1.0 生成的图像。
一个月前的SDXL 0.9版本偏好率是24.4%,低于SDXL 1.0新版26.2%的偏好
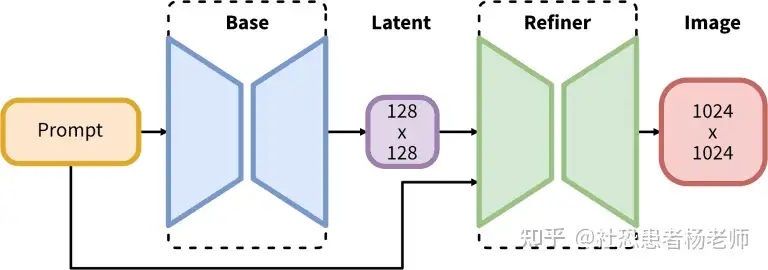
 值得注意的是,SDXL附带了2个模型和一个2步过程:基础模型可以单独使用在第一步中,基础模型生成(嘈杂)潜在因素,然后由专门用于最终去噪步骤的精炼模型进一步处理。注意,基础模型也可以作为独立模块使用,但精炼模型可以为图像增加很多锐度和质量。这种两阶段架构允许在不损害速度或需要过多计算资源的情况下实现图像生成的鲁棒性。SDXL 1.0能够有效地运行在具有8GB 显存或可用云实例的消费者GPU上。
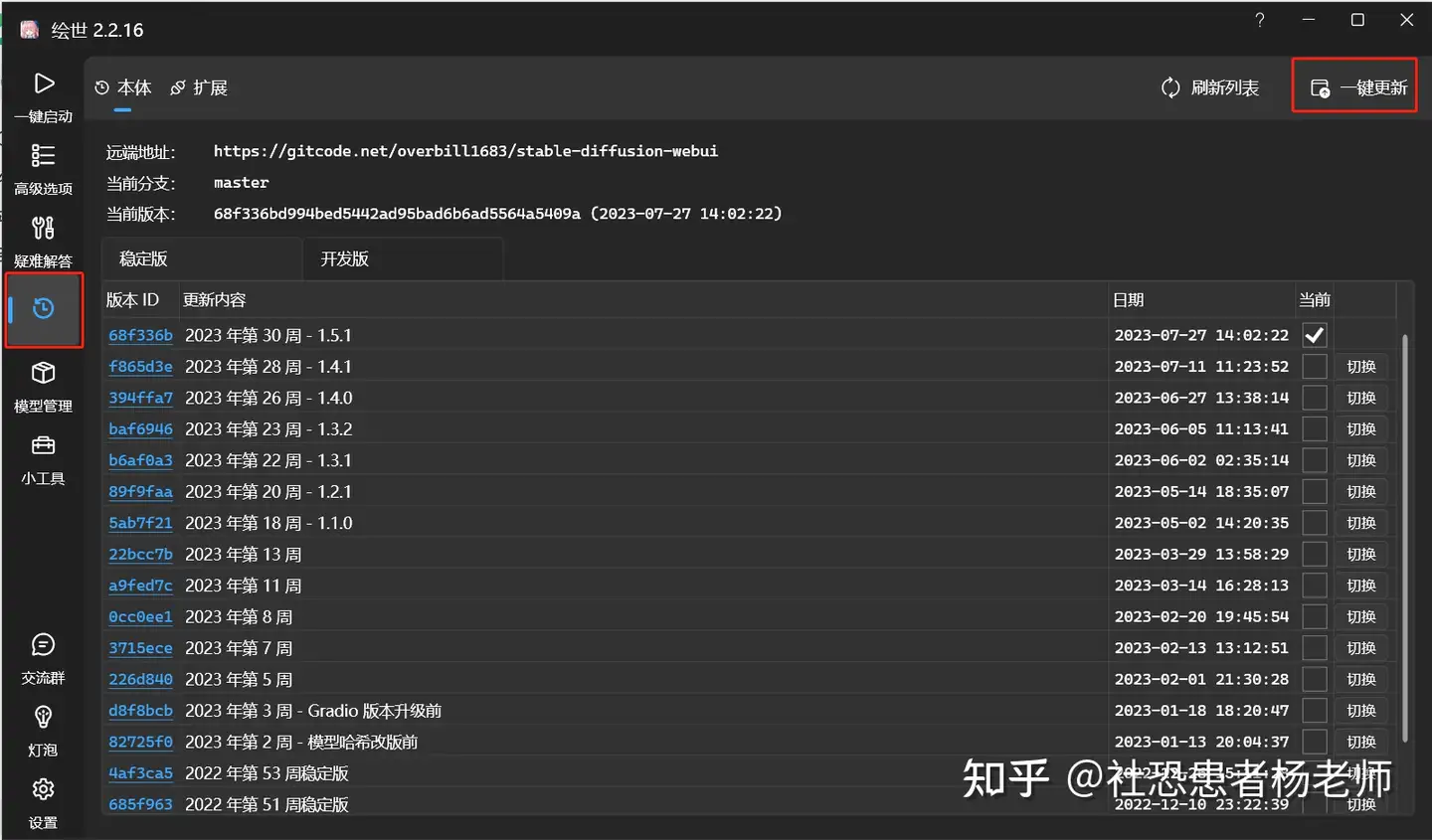
 如何使用SDXL 1.0在线使用SDXL 1.0 如何使用SDXL 1.0在线使用SDXL 1.0这里我比较推荐的是第一种Clipdrop和第四种在discord社区中使用SDXL 1.0模型。这两种方法算是最简单、最省事的方案了。 本地部署SDXL 1.0国内用户使用stable diffusion更多的还是通过秋叶大佬的启动器+WebUI的形式。因此这里就以秋叶的启动器和WebUI为例介绍一下,如何用最简单最傻瓜的方式来使用SDXL 1.0模型。首先先把启动器更新至1.5.1的版本。
打开启动器后选择左侧侧边栏的版本管理,然后点击右上角的一键更新即可。
 下载模型 下载模型下载以下两个模型文件(需要到 Files and Versions 中寻找模型文件): 下载SDXL VAE文件: 装载模型将下载好的两个模型文件放到你的SD文件夹的如下路径:stable-diffusion-webui/models/Stable-Diffusion.
然后将VAE文件放到如下路径:stable-diffusion-webui/models/VAE. 设置VAE如果您没有VAE下拉菜单:在WebUI中点击“设置”选项卡>“用户界面”子选项卡。然后在“快速设置列表”设置下添加sd_vae 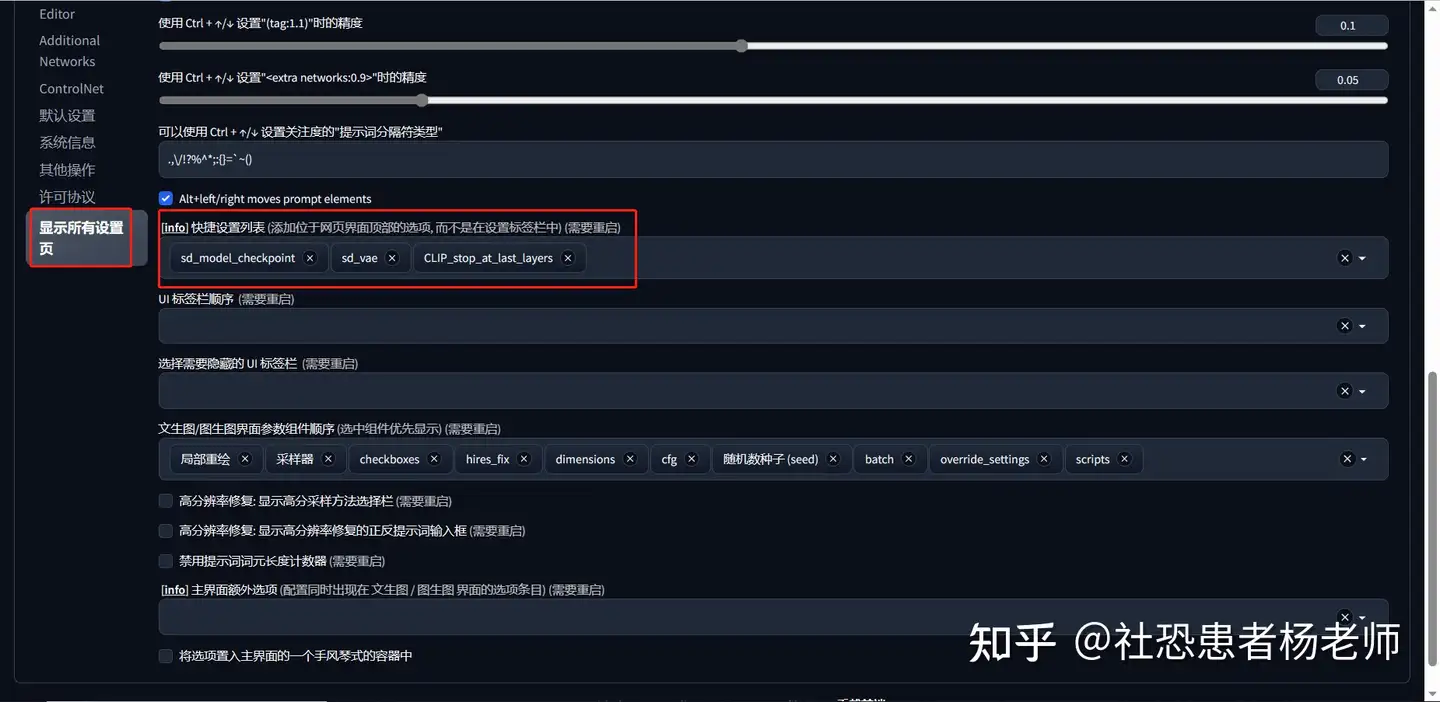 滚动到设置的顶部。点击保存设置,然后重新加载UI。现在您将在检查点模型下拉菜单旁边看到VAE下拉菜单。选择您下载的VAE,sdxl_vae.safetensors  使用SDXL 1.0 使用SDXL 1.0SDXL 1.0在WebUI中的使用方法和之前基于SD 1.5模型的方法没有太多区别,依然还是通过提示词与反向提示词来进行文生图,通过img2img来进行图生图。需要注意的是由于SDXL的基础模型是在1024x1024分辨率下设置完成的,因此有以下三点在设置上需要注意: - 分辨率: 1024 Width x 1024 Height (or 更大)
- 采样步数: 30
- 采样方法: DPM++ 2M Karras (or 其他 DPM++ 采样器)
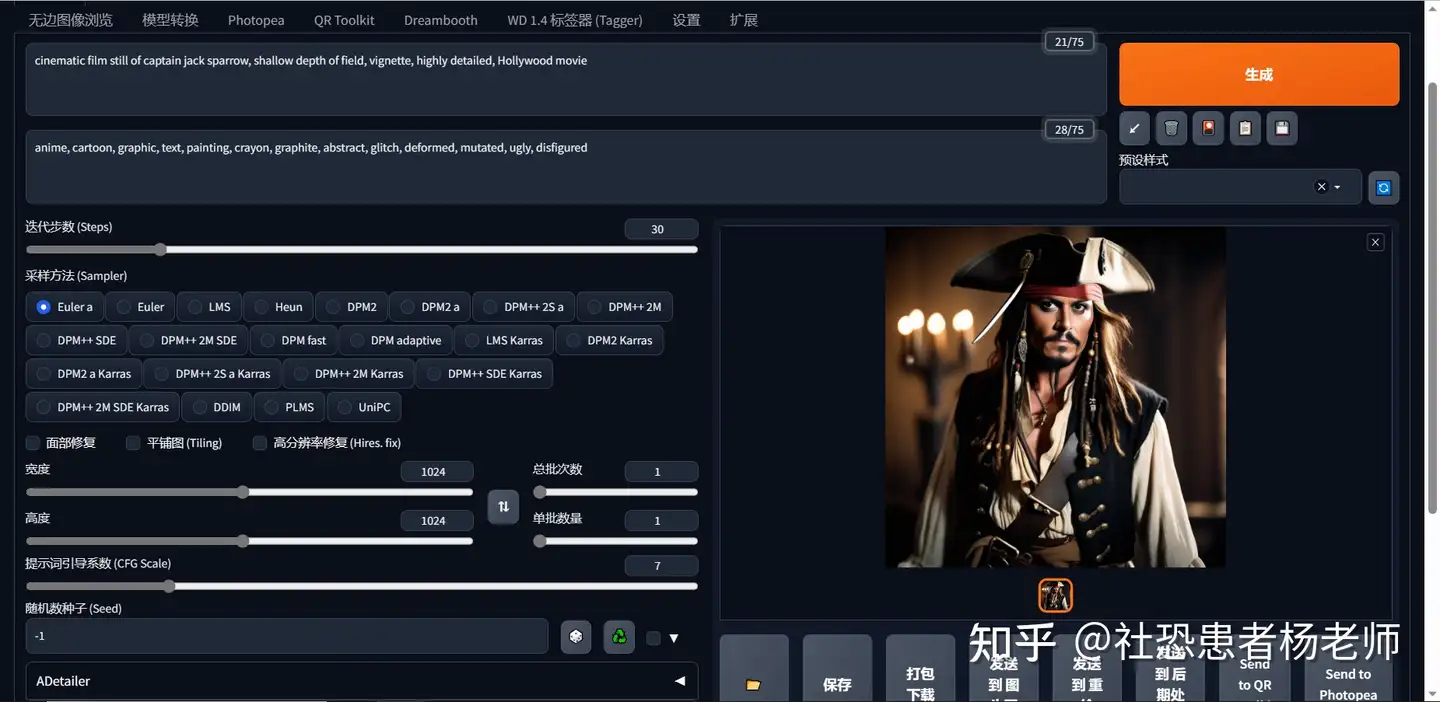 分辨率 分辨率SDXL是在1024 x 1024的图像上训练的。虽然可以以512x512的分辨率生成图像,但结果质量较低,会出现变形。为了获得最佳效果,应该将高度和宽度都保持在1024。
SDXL 1.0也支持超过1024的分辨率。这里有一些常见的分辨率,它们使用1024作为最小值,您可以尝试: - 16:9(电影摄影)1820宽度x 1024高度
- 3:2(专业摄影)1536宽度x 1024高度
- 4:3(普通图片)1365宽度x 1024高度
这里需要注意的是:您的宽高比“拉伸”越严重,出现变形和突变的可能性就越大。 采样步数在之前基于SD 1.5微调的模型中一般采样步数设置为20就能取得不错的图片。但是在SDXL中,如果将采样步数设置为20会给人一种图片精细度不够,给人一种并没有画完的感觉。因此可以将采样步数适当调大,这样可以获得更好的出图质量。当然这就需要更好的显卡和更大的现存。具体调多大,还是要根据你本地显卡的算力才取舍。
以下为使用30steps-60steps效果对比。  采样器 采样器采样方法对SDXL 1.0来说比以前的版本更重要。建议使用任何DPM++采样器,特别是带有Karras采样器的DPM++。比如DPM++ 2M Karras或DPM++ 2S a Karras。
Prompt: Portrait photo of an anthropomorphic farmer cat holding a shovel in a garden vintage film photo
Negative Prompt: anime, cartoon, graphic, text, painting, crayon, graphite, abstract, glitch, deformed, mutated, ugly, disfigured
 使用 SDXL Refiner 进行图生图 使用 SDXL Refiner 进行图生图Refiner精炼模型用于增加更多细节并使图像质量更清晰。它最适用于逼真的生成。实际上,可以通过在WebUI中使用img2img功能和低去噪(低强度)来使用它。
首先,应该下载Refiner模型并将其放置在您的模型文件夹stable-diffusion-webui/models/Stable-Diffusion中。
然后,像往常一样使用SDXL 1.0基础模型生成图像。在图像下方,点击“发送到img2img” 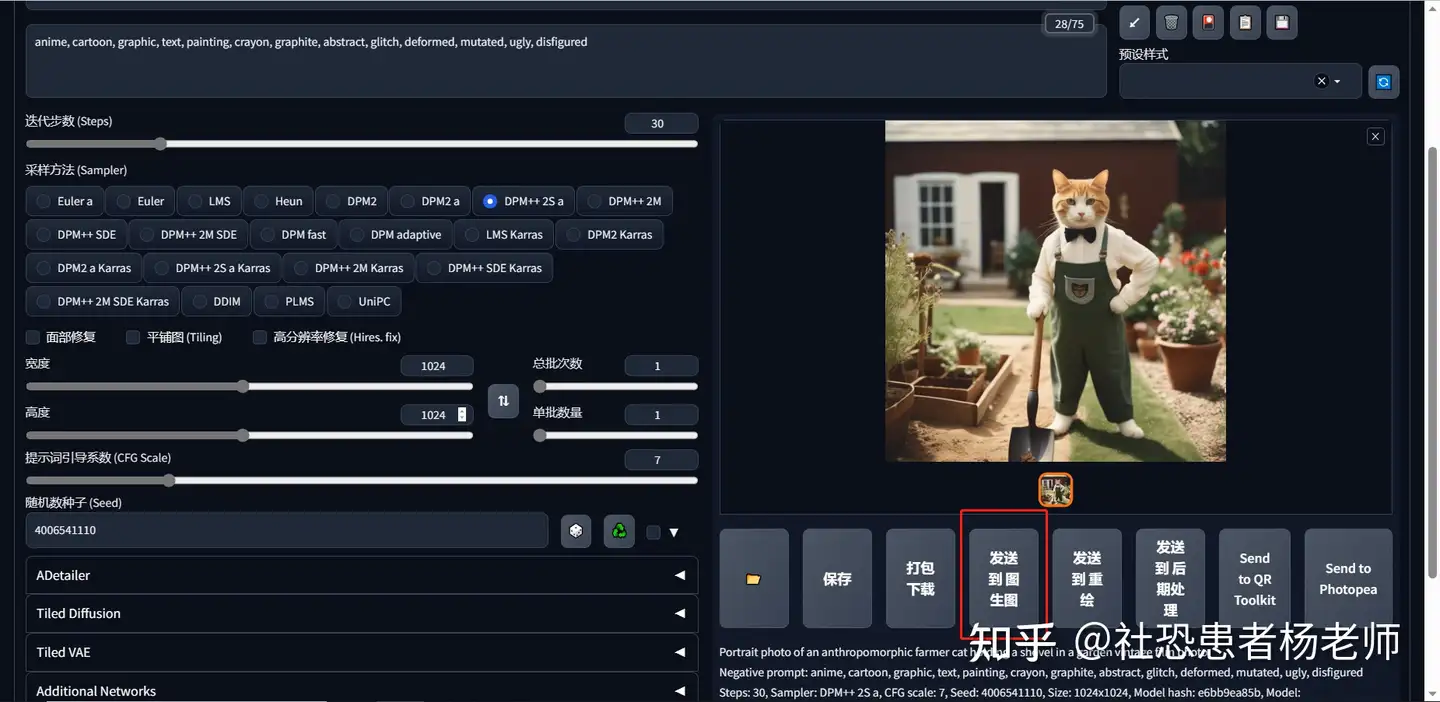 此时图像已经在img2img选项卡中打开。
然后开始进行以下更改:
在Stable Diffusion模型下拉菜单中,选择sd_xl_refiner_1.0.safetensors。 在“调整大小”部分,将宽度和高度更改为1024 x 1024(或您原始生成的尺寸)。 将重绘幅度调整为0.25(更高的重绘幅度会使refiner的效果更强。虽然这可以使图像更清晰,但也会大大改变图像的内容) 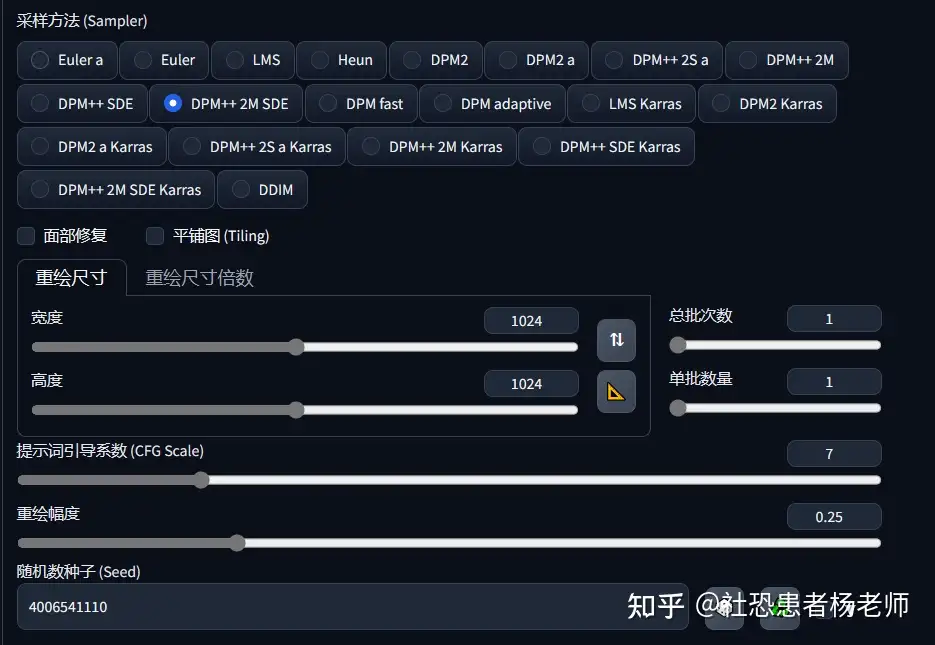 以下为使用不同重绘幅度生成的4张图片,通过对比可以看出虽然0.75重绘幅度生成的图片清晰度最高,但是和原始图片相比较,已经完全不是同一张图了,因此具体的重绘幅度设置为多少比较合适,还需要根据你的目标来设置。不是越高越好,并且太高的重绘幅度很多时候生成的图片都会存在非常多不合理的地方,这会导致重绘后的图片完全无法使用。  Aesthetic Scores美学得分 Aesthetic Scores美学得分Aesthetic Score美学得分是 SDXL 模型附带的一个新设置。这仅用于refiner精炼模型。SDXL的训练数据中每张图像都有一个美学分数,0表示最丑,10表示最好看。通过设置您的 SDXL 高美学评分,您将提示偏向具有该美学评分的图像(理论上提高您图像的美学)。
在模型训练阶段,模型的 U-Net “骨架”使用这些分数作为额外的“调节指南”。这种指南尝试弄清楚是什么让一幅画获得高分,而什么不能。那么我们应该如何理解Aesthetic Score美学得分呢?
假设在训练期间,我们有很多质量较差的图,例如,在粗糙木材做的桌子上的红苹果。模型可能会开始将红苹果和粗糙木材桌子与“质量差”的艺术联系起来,仅仅因为有这么多低质量的例子。
在这种情况下,一幅高分画作也恰好以红苹果和粗糙木材做的桌子为特征,可能不会被充分捕捉到其特征,并且只产生质量较差的红苹果。
这就是美学分数发挥作用的地方。因为它是“文本嵌入”的一部分,所以它被视为标题的一部分。模型在学习过程中“考虑”每幅画作的美学评分,并在推理过程中使用给定评分来减少对低评分画作特征的重视。这样,输出就不会过于偏向少数(甚至许多)“不好”的例子。因此,用于后续微调的数据集质量并不像您预期的那样影响 AI 创造美丽作品的能力。
SDXL 低美学评分有点让人令人困惑。它设置了负面提示词的“偏见”。通常,希望这种偏见类似于具有低美学评分的图像。因此这与高美学评分相反。此值越低,你的图像看起来就越好,反之亦然。
要更改美学评分,需要到“设置”选项卡-> SDXL 子选项卡中进行设置。 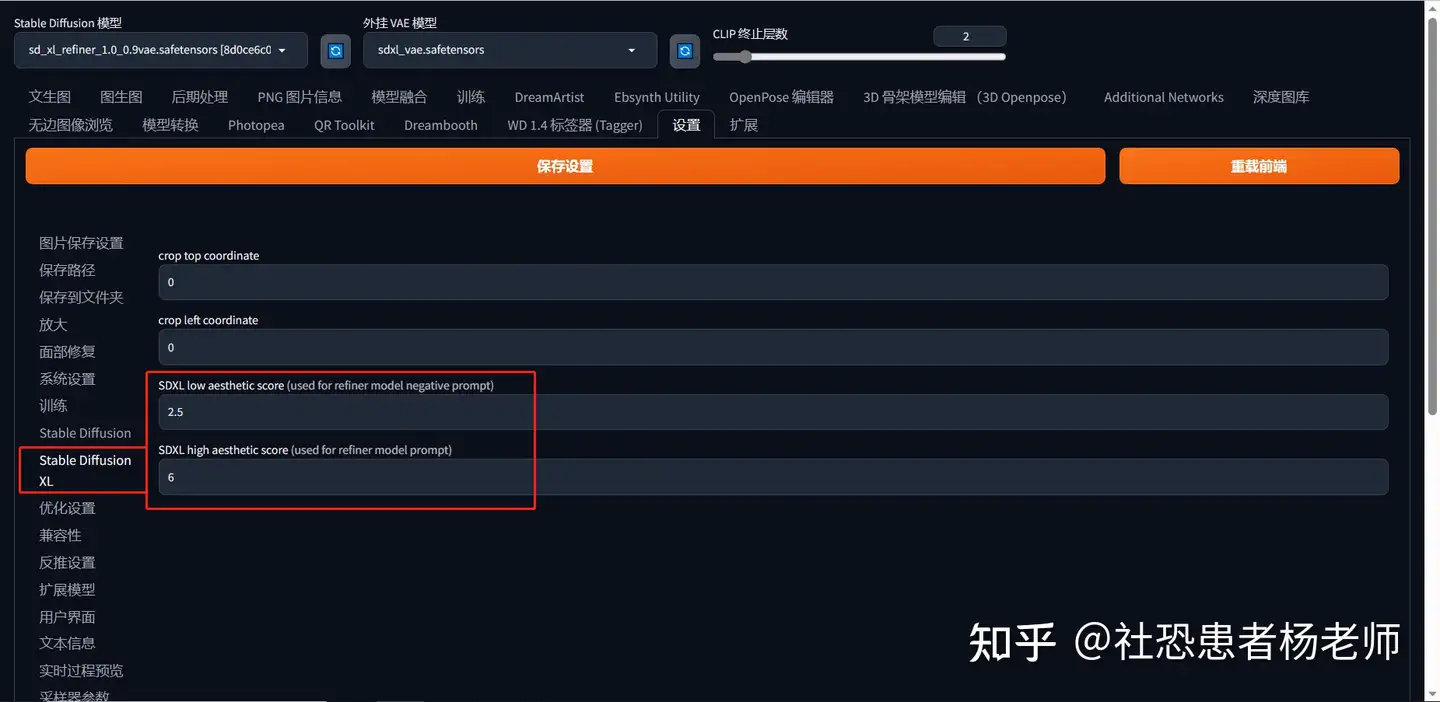 其中:SDXL low aesthetic score默认值为2.5,SDXL high aesthetic score默认值为6
基于下面这张文生图生成的图片使用SDXL 1.0 refiner model将重绘幅度调整为0.5,然后使用四种不同的美学评分组合参数绘制出四张不同的图片。
Prompt: cinematic photo of a lady. 35mm photograph, film, bokeh, professional, 4k, highly detailed
Negative Prompt: deformed, glitch, noise, noisy, off-center, deformed, cross-eyed, closed eyes, bad anatomy, ugly, disfigured, sloppy, duplicate, mutated, black and white
  很明显,将低分设置为 0,将高分设置为 10 并不一定会产生最好的图像。有点讽刺的是,结合“低质量”图像的粗糙度会使图像看起来更好,更真实。不同的美学风格将有最适合的不同美学评分。
下面是一些不同风格的推荐值。 - 现实主义/摄影:1 low score,5 high score(如上所示)
- 传统媒介绘画:1 low score,8 high score
- 数字绘画:4 low score,9 high score
或者直接使用默认的2.5 low score,6 high score也是不错的选择。 自定义模型与Lora不同于SD1.5的基础模型是用512x512的size训练的,SDXL 1.0的基础模型都是使用1024x1024的size图片训练得到的。因此这也就意味着之前基于SD1.5fine-tunes得到的模型和Lora全部都失效不能基于SDXL 1.0使用。
目前C站release出来的基于SDXL 1.0微调得到的模型,只找到两个。但是随着时间的推移,未来基于SDXL 1.0基础模型微调的模型和Lora一定会越来越多,效果也会越来越好,这就是开源社区的强大之处!   可能遇到的问题 可能遇到的问题
URLError: <urlopen error [WinError 10054] 远程主机强迫关闭了一个现有的连接。>################################################################Repo already cloned, using it as install directory################################################################################################################################Create and activate python venv################################################################################################################################Launching launch.py...################################################################Python 3.10.6 (main, Oct 24 2022, 11:04:07) [Clang 12.0.0 ]Version: v1.5.1Commit hash: 68f336bd994bed5442ad95bad6b6ad5564a5409aLaunching Web UI with arguments: --skip-torch-cuda-test --medvram --no-half-vaeno module 'xformers'. Processing without...no module 'xformers'. Processing without...No module 'xformers'. Proceeding without it.Warning: caught exception 'Torch not compiled with CUDA enabled', memory monitor disableddirname: /Users/block/code/sd/stable-diffusion-webui/localizationslocalizations: {'zh_CN': '/Users/block/code/sd/stable-diffusion-webui/extensions/stable-diffusion-webui-localization-zh_CN/localizations/zh_CN.json', 'zh_TW': '/Users/block/code/sd/stable-diffusion-webui/extensions/stable-diffusion-webui-localization-zh_TW/localizations/zh_TW.json'}2023-07-28 15:22:55,564 - ControlNet - INFO - ControlNet v1.1.233ControlNet preprocessor location: /Users/block/code/sd/stable-diffusion-webui/extensions/sd-webui-controlnet/annotator/downloads2023-07-28 15:22:55,608 - ControlNet - INFO - ControlNet v1.1.233Loading weights [1f69731261] from /Users/block/code/sd/stable-diffusion-webui/models/Stable-diffusion/Stable Diffusion XL 0.9_base.safetensorsRunning on local URL: http://127.0.0.1:7860To create a public link, set `share=True` in `launch()`.Startup time: 5.2s (launcher: 0.4s, import torch: 1.4s, import gradio: 0.5s, setup paths: 0.6s, other imports: 0.5s, load scripts: 0.6s, create ui: 0.6s, gradio launch: 0.4s).Creating model from config: /Users/block/code/sd/stable-diffusion-webui/repositories/generative-models/configs/inference/sd_xl_base.yamlCouldn't find VAE named vae-ft-mse-840000-ema-pruned.safetensors; using None insteadApplying attention optimization: InvokeAI... done.Model loaded in 63.8s (load weights from disk: 1.1s, create model: 0.6s, apply weights to model: 27.8s, apply half(): 31.6s, hijack: 0.2s, load textual inversion embeddings: 0.2s, calculate empty prompt: 2.1s).Downloading VAEApprox model to: /Users/block/code/sd/stable-diffusion-webui/models/VAE-approx/vaeapprox-sdxl.pt*** Error completing request*** Arguments: ('task(zxfewnh4tcmf35o)', 'best quality, masterpiece, ultra highresolution,(photorealistic:1.37).\n1girl, cute,slim, light blush,red\neyes,ponytail,long hair, dark\neyes,profile,(medium breasts),croptop, Gradient background,', '', [], 20, 0, False, False, 1, 1, 7, -1.0, -1.0, 0, 0, 0, False, 512, 512, False, 0.7, 2, 'Latent', 0, 0, 0, 0, '', '', [], <gradio.routes.Request object at 0x31fbebee0>, 0, <scripts.controlnet_ui.controlnet_ui_group.UiControlNetUnit object at 0x2b7d44a60>, False, False, 'positive', 'comma', 0, False, False, '', 1, '', [], 0, '', [], 0, '', [], True, False, False, False, 0, None, None, False, 50) {} Traceback (most recent call last): File "/Users/block/anaconda3/envs/py3_10_6_sd/lib/python3.10/urllib/request.py", line 1348, in do_open h.request(req.get_method(), req.selector, req.data, headers, File "/Users/block/anaconda3/envs/py3_10_6_sd/lib/python3.10/http/client.py", line 1282, in request self._send_request(method, url, body, headers, encode_chunked) File "/Users/block/anaconda3/envs/py3_10_6_sd/lib/python3.10/http/client.py", line 1328, in _send_request self.endheaders(body, encode_chunked=encode_chunked) File "/Users/block/anaconda3/envs/py3_10_6_sd/lib/python3.10/http/client.py", line 1277, in endheaders self._send_output(message_body, encode_chunked=encode_chunked) File "/Users/block/anaconda3/envs/py3_10_6_sd/lib/python3.10/http/client.py", line 1037, in _send_output self.send(msg) File "/Users/block/anaconda3/envs/py3_10_6_sd/lib/python3.10/http/client.py", line 975, in send self.connect() File "/Users/block/anaconda3/envs/py3_10_6_sd/lib/python3.10/http/client.py", line 1447, in connect super().connect() File "/Users/block/anaconda3/envs/py3_10_6_sd/lib/python3.10/http/client.py", line 941, in connect self.sock = self._create_connection( File "/Users/block/anaconda3/envs/py3_10_6_sd/lib/python3.10/socket.py", line 845, in create_connection raise err File "/Users/block/anaconda3/envs/py3_10_6_sd/lib/python3.10/socket.py", line 833, in create_connection sock.connect(sa) TimeoutError: [Errno 60] Operation timed out During handling of the above exception, another exception occurred: Traceback (most recent call last): File "/Users/block/code/sd/stable-diffusion-webui/modules/call_queue.py", line 58, in f res = list(func(*args, **kwargs)) File "/Users/block/code/sd/stable-diffusion-webui/modules/call_queue.py", line 37, in f res = func(*args, **kwargs) File "/Users/block/code/sd/stable-diffusion-webui/modules/txt2img.py", line 62, in txt2img processed = processing.process_images(p) File "/Users/block/code/sd/stable-diffusion-webui/modules/processing.py", line 677, in process_images res = process_images_inner(p) File "/Users/block/code/sd/stable-diffusion-webui/extensions/sd-webui-controlnet/scripts/batch_hijack.py", line 42, in processing_process_images_hijack return getattr(processing, '__controlnet_original_process_images_inner')(p, *args, **kwargs) File "/Users/block/code/sd/stable-diffusion-webui/modules/processing.py", line 738, in process_images_inner sd_vae_approx.model() File "/Users/block/code/sd/stable-diffusion-webui/modules/sd_vae_approx.py", line 53, in model download_model(model_path, 'https://github.com/AUTOMATIC1111/stable-diffusion-webui/releases/download/v1.0.0-pre/' + model_name) File "/Users/block/code/sd/stable-diffusion-webui/modules/sd_vae_approx.py", line 39, in download_model torch.hub.download_url_to_file(model_url, model_path) File "/Users/block/anaconda3/envs/py3_10_6_sd/lib/python3.10/site-packages/torch/hub.py", line 611, in download_url_to_file u = urlopen(req) File "/Users/block/anaconda3/envs/py3_10_6_sd/lib/python3.10/urllib/request.py", line 216, in urlopen return opener.open(url, data, timeout) File "/Users/block/anaconda3/envs/py3_10_6_sd/lib/python3.10/urllib/request.py", line 519, in open response = self._open(req, data) File "/Users/block/anaconda3/envs/py3_10_6_sd/lib/python3.10/urllib/request.py", line 536, in _open result = self._call_chain(self.handle_open, protocol, protocol + File "/Users/block/anaconda3/envs/py3_10_6_sd/lib/python3.10/urllib/request.py", line 496, in _call_chain result = func(*args) File "/Users/block/anaconda3/envs/py3_10_6_sd/lib/python3.10/urllib/request.py", line 1391, in https_open return self.do_open(http.client.HTTPSConnection, req, File "/Users/block/anaconda3/envs/py3_10_6_sd/lib/python3.10/urllib/request.py", line 1351, in do_open raise URLError(err) urllib.error.URLError: <urlopen error [Errno 60] Operation timed out>
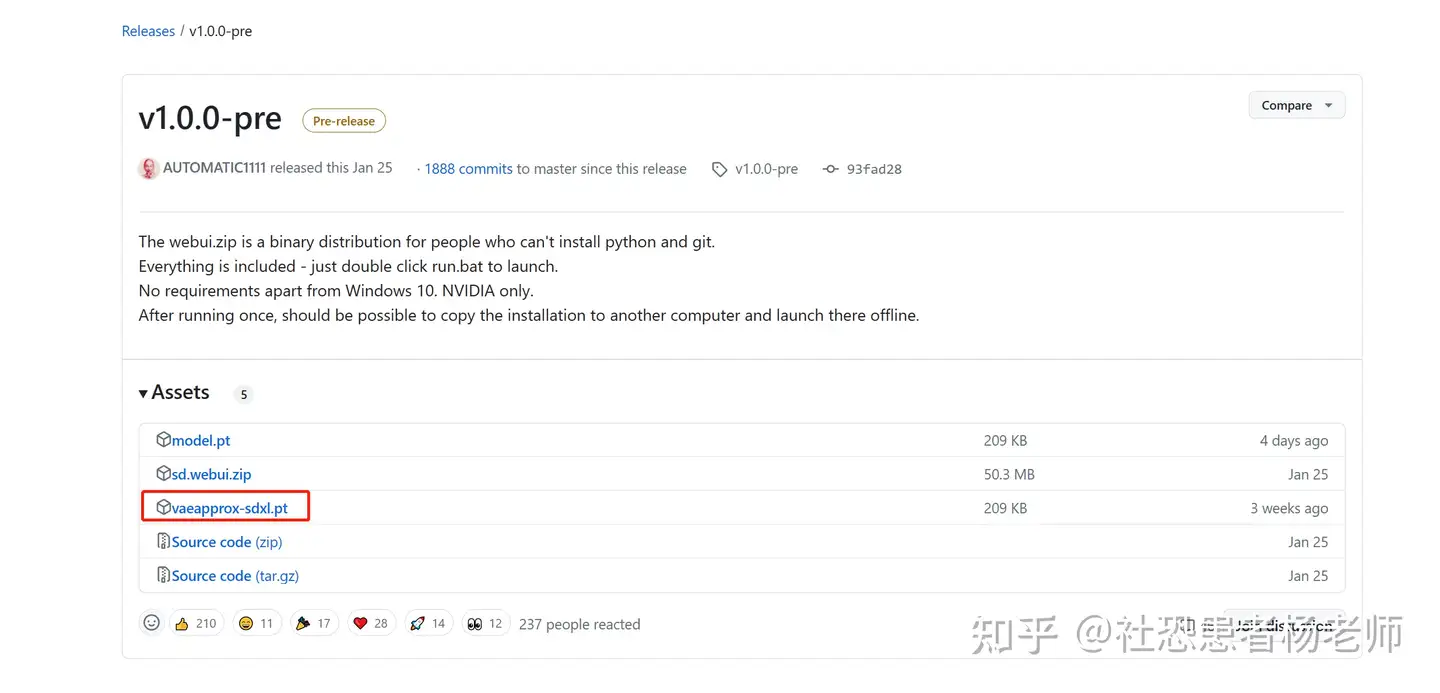 点击下载该文件,然后放到你本地SD文件夹中的下面这个路径,然后重新载入WebUI即可解决。 文件放置路径: \sd-webui-aki-v4.1\models\VAE-approx\ Error: torch.cuda.Out Of MemoryError: CUDA out of memorySDXL 占用的显存是比SD 2.1 和SD 1.5更高的, 因此如果之前你的显存刚刚够用的话,很可能会报OOM的error
解决方案就是在启动器中开启低显存模式以及使用,或者换一个显存更大的显卡。 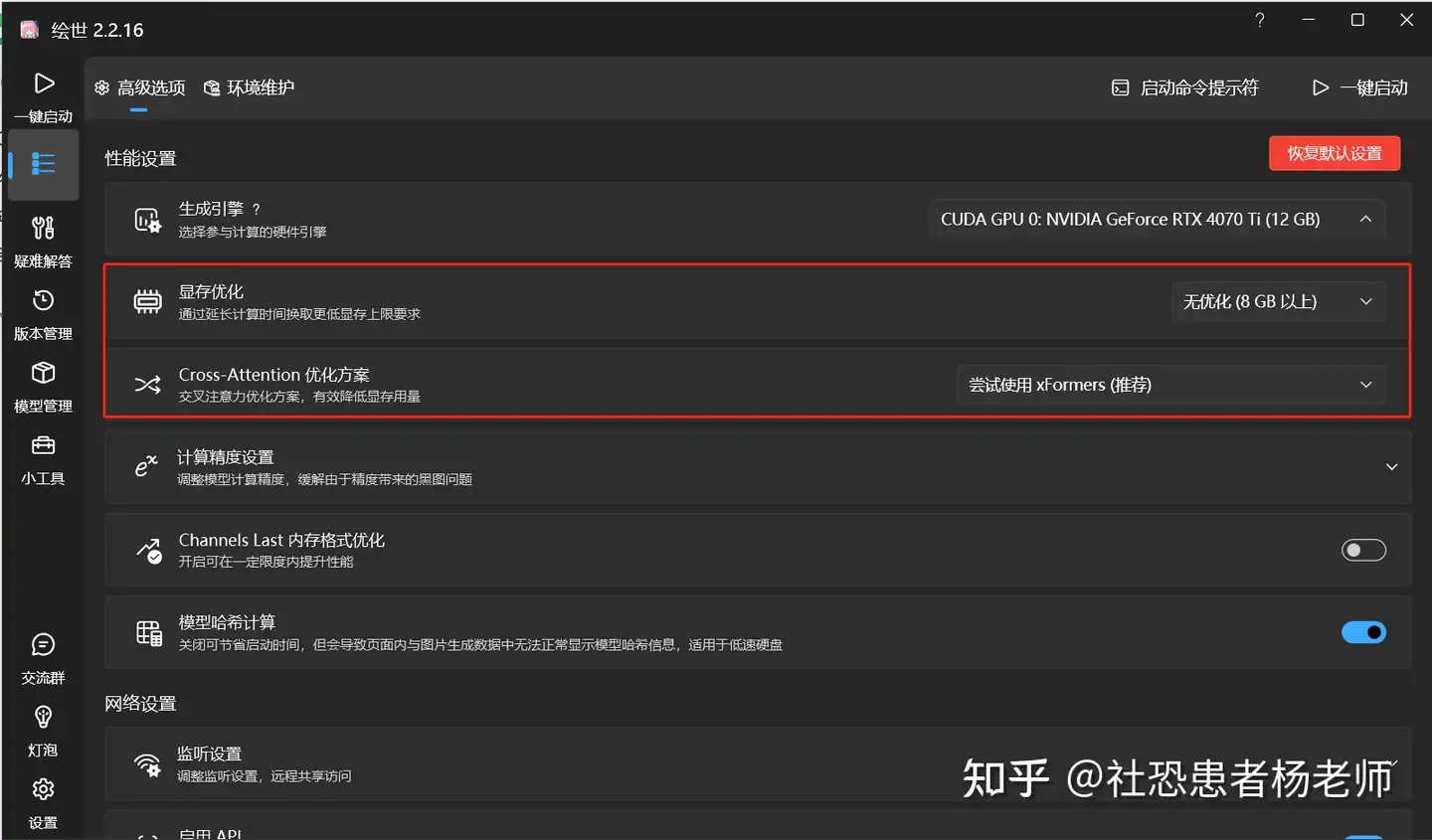 模型载入卡住不动 模型载入卡住不动如果在选择模型的时候一直载入SDXL 1.0长时间没有反应。可以尝试以下方法: - 更新 xformers (xformers: 0.0.20 or later)
- 禁用插件
更新 xformers :
首先在你的SD文件夹中找到WebUI的批处理命令文件(Windows系统),如果是Linux则应该找到WebUI.shell的脚本文件。 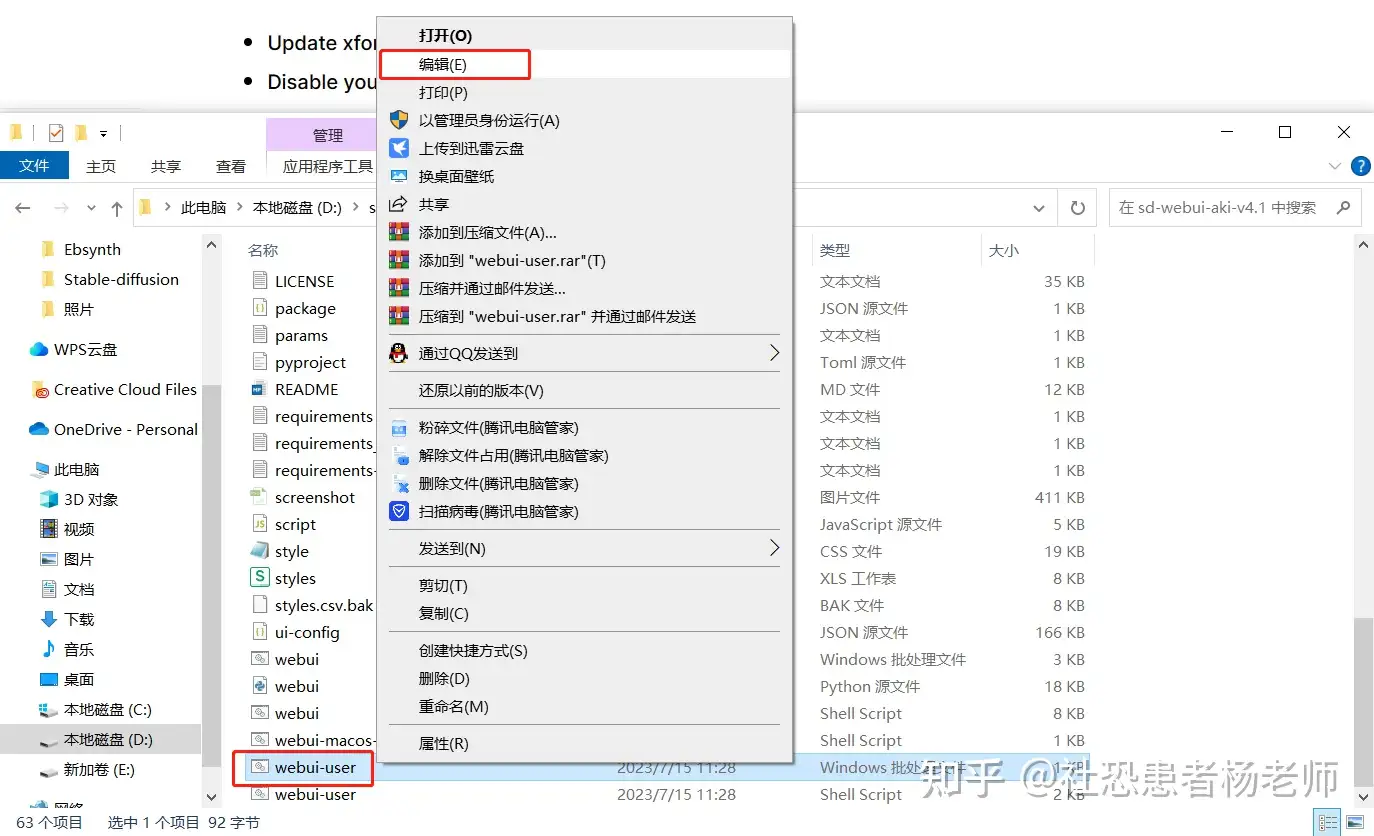 然后点击编辑之后添加一行: "set COMMANDLINE_ARGS=" add "--xformers"  保存后双击运行WebUI批处理文件,然后再重启启动器即可。
禁用插件:
在扩展中选择已安装,然后点击停用全部扩展,在应用更改重启前端。 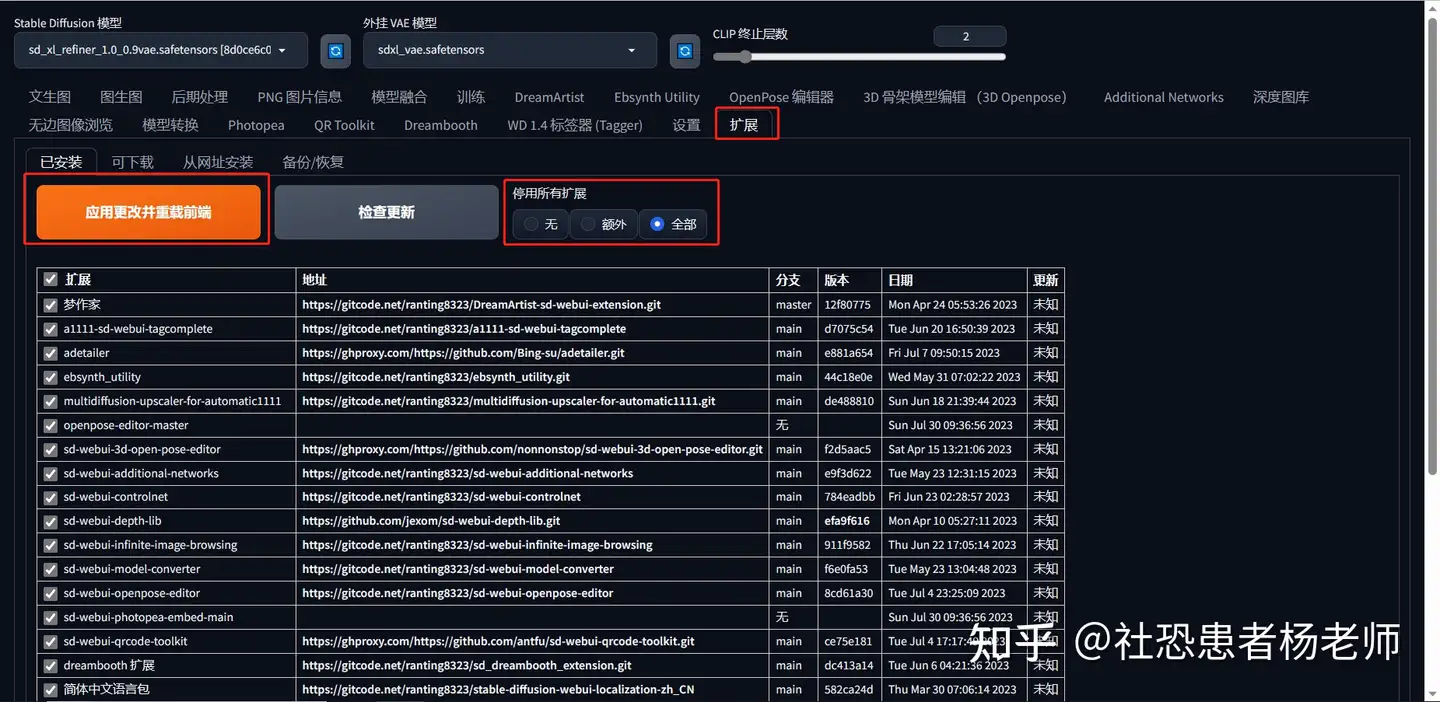 关于SDXL能否在Mac M1上运行 可以在M1是运行,但是速度非常慢,非常不推荐非N卡用户本地运行SD。
|
 |Archiver|手机版|小黑屋|吹友吧
( 京ICP备05078561号 )
|Archiver|手机版|小黑屋|吹友吧
( 京ICP备05078561号 )


 狗仔卡
狗仔卡 发表于 2024-1-7 16:34
发表于 2024-1-7 16:34
 提升卡
提升卡 变色卡
变色卡 显身卡
显身卡