|
Vicuna: An Open-Source Chatbot Impressing GPT-4 with Vicuna: An Open-S项目在 [size=1em]https://vicuna.lmsys.org/ 以下是中文介绍
2023-04-05 20:51 出品 | OSC开源社区(ID:oschina2013)
大型语言模型 (LLM) 的快速发展彻底改变了聊天机器人系统,从而实现了前所未有的智能水平,譬如 OpenAI 的 ChatGPT。但 ChatGPT 的训练和架构细节仍不清楚,阻碍了该领域的研究和开源创新。受 Meta LLaMA 和 Stanford Alpaca 项目的启发,来自加州大学伯克利分校、CMU、斯坦福大学和加州大学圣地亚哥分校的成员,共同推出了一个 Vicuna-13B 开源聊天机器人,由增强的数据集和易于使用、可扩展的基础设施支持。 根据介绍,通过根据从 ShareGPT.com (一个用户可以分享他们的 ChatGPT 对话的网站) 收集的用户共享对话微调 LLaMA 基础模型,Vicuna-13B 与 Stanford Alpaca 等其他开源模型相比展示了具有竞争力的性能。 以 GPT-4 为评判标准的初步评估显示,Vicuna-13B 达到了 OpenAI ChatGPT 和 Google Bard 90% 以上的质量,同时在 90% 以上的情况下超过了 LLaMA 和 Stanford Alpaca 等其他模型的表现。训练 Vicuna-13B 成本约为 300 美元。训练和服务代码,以及在线演示 都是公开的,可用于非商业用途。 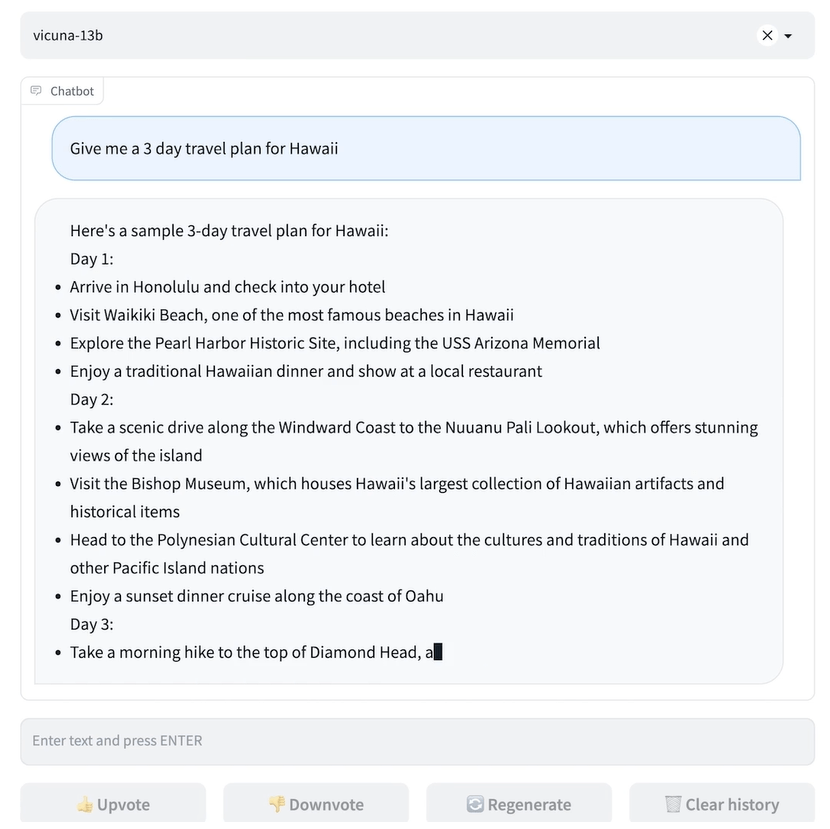
为了确保数据质量,Vicuna 团队 将 HTML 转换回 markdown 并过滤掉一些不合适或低质量的样本。以及将冗长的对话分成更小的部分,以适应模型的最大上下文长度。其训练方法建立在 Stanford Alpaca 的基础上,并进行了以下改进: - 内存优化: 为了使 Vicuna 能够理解长上下文,开发团队将最大上下文长度从 Alpaca 中的 512 扩展到 2048,大大增加了 GPU 内存需求。通过利用 utilizing gradient checkpointing 和 flash attention 来解决内存压力。
- 多轮对话: 调整训练损失以考虑多轮对话,并仅根据聊天机器人的输出计算微调损失。
- 通过 Spot 实例降低成本: 40 倍大的数据集和 4 倍的训练序列长度对训练费用提出了相当大的挑战。Vicuna 团队使用 SkyPilot managed spot 来降低成本,方法是利用更便宜的 spot 实例以及自动恢复抢占和自动区域切换。该解决方案将 7B 模型的训练成本从 500 美元削减至 140 美元左右,将 13B 模型的训练成本从 1000 美元左右削减至 300 美元。
Vicuna 团队构建了一个服务系统,该系统能够使用分布式 workers 为多个模型提供服务;它支持来自本地集群和云的 GPU worker 的灵活插件。通过利用 SkyPilot 中的容错控制器和 managed spot 功能,该服务系统可以很好地与来自多个云的更便宜的 spot 实例一起工作,以降低服务成本。它目前是一个轻量级的实现,未来将努力将集成更多的最新研究成果 。 具体来说,开发团队首先从 ShareGPT.com 收集了大约 7 万个对话,然后增强了 Alpaca 提供的训练脚本,以更好地处理多轮对话和长序列;训练在一天内在 8 个 A100 GPU 上使用 PyTorch FSDP 完成。为了提供演示服务,他们还实现了一个轻量级的分布式服务系统。通过创建一组 80 个不同的问题并利用 GPT-4 来判断模型输出,对模型质量进行了初步评估。为了比较两个不同的模型,团队成员将每个模型的输出组合成每个问题的单个提示。然后将提示发送到 GPT-4,GPT-4 评估哪个模型提供更好的响应。 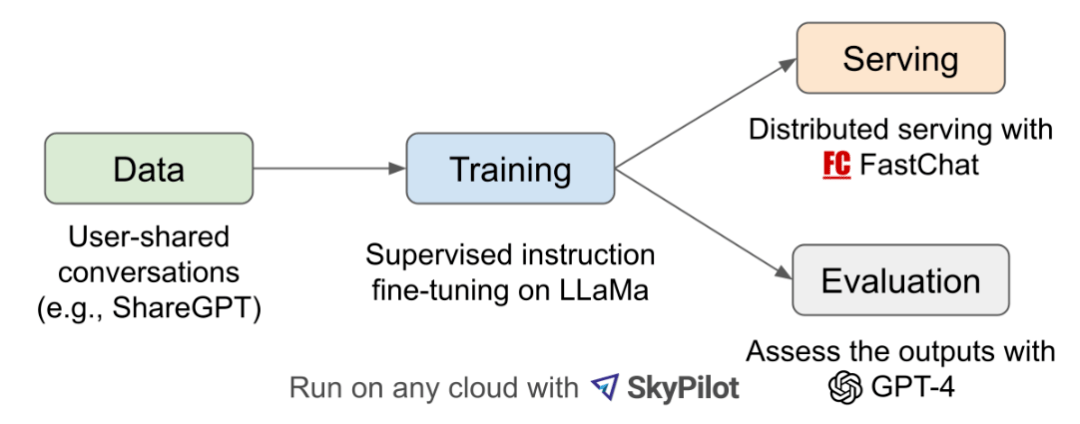 LLaMA、Alpaca、ChatGPT 和 Vicuna 的详细对比如下: 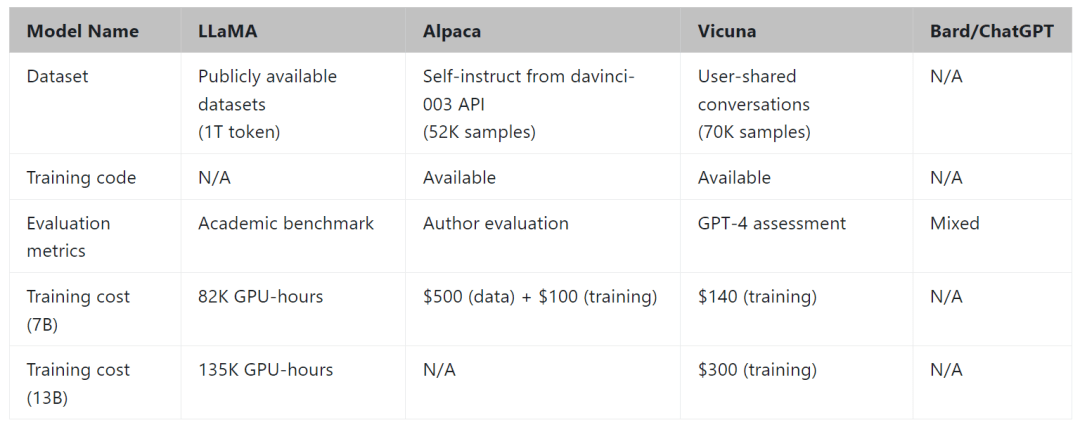 Vicun 团队展示了 Alpaca 和 Vicuna 对基准问题的回答示例。在使用 70K 用户共享的 ChatGPT 对话对 Vicuna 进行微调后,其发现与 Alpaca 相比,Vicuna 能够生成更详细、结构更合理的答案,并且质量与 ChatGPT 相当。 例如,在要求 “撰写一篇引人入胜的旅游博文,介绍最近的夏威夷之行,突出文化体验和必去的景点” 时,GPT-4 的评价得分为:Alpaca-13b 7/10,Vicuna-13b 10/10。并阐述理由称,Alpaca 提供了旅行博文的简要概述,但没有按照要求实际撰写博文,导致得分较低。Vicuna-13b 则就最近的夏威夷之行撰写了一篇详细而有吸引力的旅游博文,强调了文化体验和必看的景点,完全满足了用户的要求,因此获得了较高的分数。 与此同时,Vicun 的初步发现表明,在比较聊天机器人的答案时,GPT-4 可以产生高度一致的等级和详细的评估。下图中总结的基于 GPT-4 的初步评估显示,Vicuna 达到了 Bard/ChatGPT 的 90% 能力。不过总的来说,为聊天机器人建立一个评估系统仍是一个需要进一步研究的开放式问题。 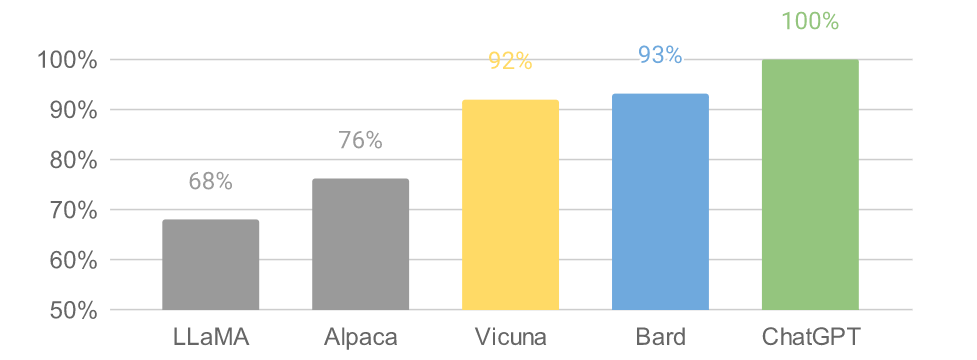 Vicun 团队 提出了一个基于 GPT-4 的评估框架来自动评估聊天机器人的性能。设计了八个问题类别,以测试聊天机器人性能的各个方面。并基于每个类别选择十个问题,分别由 LLaMA、Alpaca、ChatGPT、Bard 和 Vicuna 生成答案,然后要求 GPT-4 根据有用性、相关性、准确性和细节来评估答案质量。结果发现 GPT-4 不仅可以产生相对一致的分数,而且可以详细解释为什么给出这样的分数(详细示例 链接 )。但在判断编码 / 数学任务方面,GPT-4 则不太擅长。 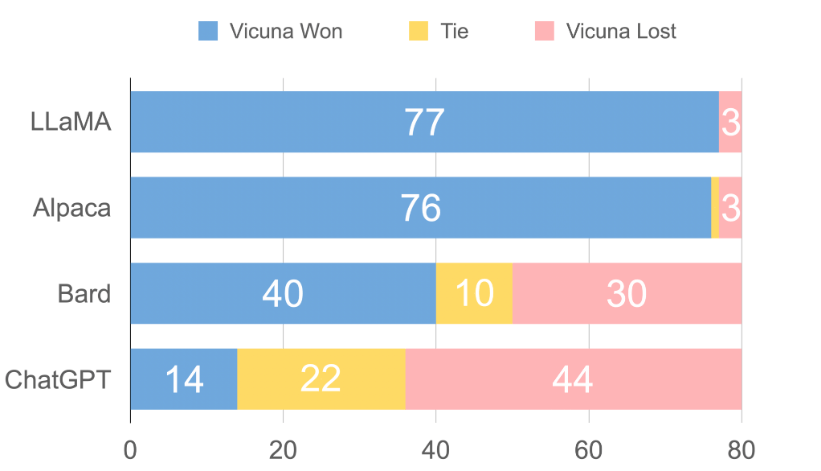 数据表明在超过 90% 的问题中,相较 LLaMA、Alpaca 等,GPT-4 更倾向 Vicuna 生成的答案,并且它实现了可与专有模型(ChatGPT、Bard)竞争的性能。在 45% 的问题中,GPT-4 将 Vicuna 的回答评为优于或等于 ChatGPT 的回答。 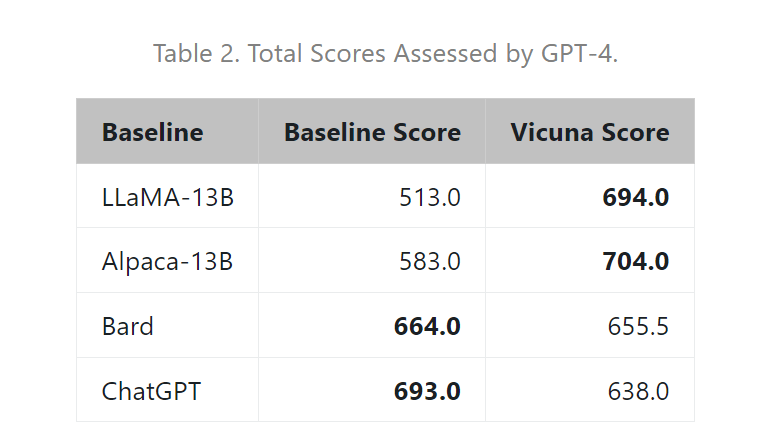 总的来说,虽然最近行业发展如火如荼,但事实上聊天机器人仍然面临局限性,例如难以解决基本的数学问题或编码能力有限。且为聊天机器人开发一个全面、标准化的评估系统,也是一个需要进一步研究的悬而未决的问题。 开发团队承认,Vicuna 不擅长涉及推理或数学的任务,并且在准确识别自己或确保其输出的事实准确性方面可能存在局限性。此外,它还没有得到充分优化以保证安全性或减轻潜在的毒性或偏见。为了解决安全问题,他们使用 OpenAI moderation API 来过滤掉在线演示中不适当的用户输入。 从开源到商业,从技术到生态,GOTC 2023开源盛会即将开启 中兴新支点OS桌面环境正式开源,仅104M,速度提升20% Twitter算法开源
Open Source Chatbot Impressing GPT-4 with 90%*ChatGPT Quality
|  |Archiver|手机版|小黑屋|吹友吧
( 京ICP备05078561号 )
|Archiver|手机版|小黑屋|吹友吧
( 京ICP备05078561号 )


 狗仔卡
狗仔卡 发表于 2023-4-10 21:58
发表于 2023-4-10 21:58
 提升卡
提升卡 变色卡
变色卡 显身卡
显身卡