https://zhuanlan.zhihu.com/p/648330365
一、前言其实想写LORA模型训练很久了,一直没时间,总结一下现在主流的两种LORA模型训练方式,分别是朱尼酱的赛博丹炉和秋叶大佬的训练脚本,训练效果应该是赛博丹炉更好,我个人更推荐朱尼酱的赛博丹炉,界面炫酷,操作简单,作者也是花了很多心思的。我会逐一介绍两种LORA模型训练方法。
二、朱尼酱的赛博丹炉
1.介绍- 全新U升级,赛博炼丹、科技修仙:大功能
- 首页新增产品,建筑两个训川练预设:
- 升级中英文双语TAG编辑器,支持实时翻译中英文输入TAG:
- 新增自定义参数,正则化训川练集功能:
- 新增自定义参数,分层训练功能:易用性
- 更换wd14 tagger标签器(可自定义可信度阈值
- 更换anime抠图核心,同时兼容二次元与真人
- 优化自定义参数,学习率增加加减按钮功能,方便调整
- 新增参数预设管理器功能,可自定义并管理自己的预设参数(支持中文预设名)
- 输出训川练参数到模型文件夹,方便统计xyz信息
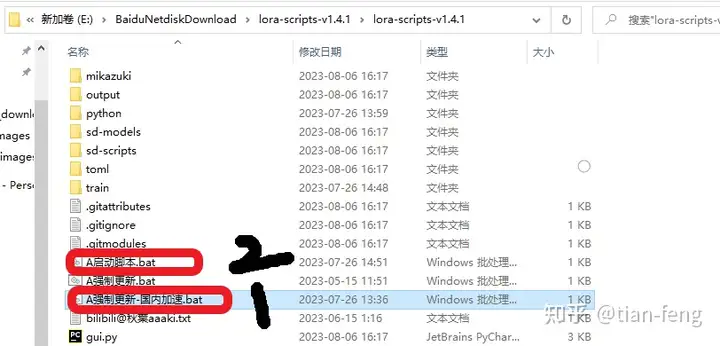
最新的赛博丹炉已经整合到道玄界面了,就是一个新的压缩包文件,里面不仅可以使用赛博丹炉训练LORA模型,还可以在上面生图,但是对我来说用处不大,我只需要他的训练脚本,因为习惯在秋叶启动器使用了,而且更方便更全面,不过如果有新手伙伴想用的话,可以去使用支持一下博主,这里给出链接。朱尼酱B站链接 https://www.bilibili.com/video/BV1tV411N7H7/
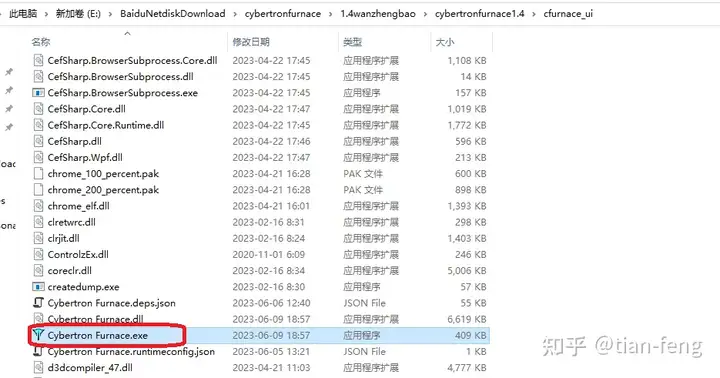
2.解压配置下载完百度网盘压缩包后,解压后点击 \cybertronfurnace1.4\cfurnace_ui\Cybertron Furnace.exe
第一次打开会下载一些文件,请耐心等待!直到出现server start


3.使用开启炼丹炉,让我们使用把!
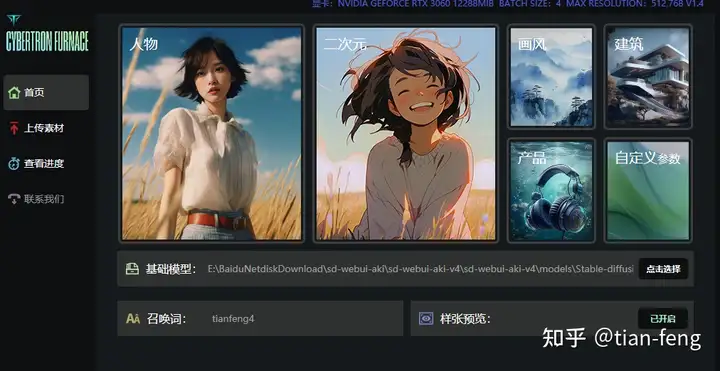
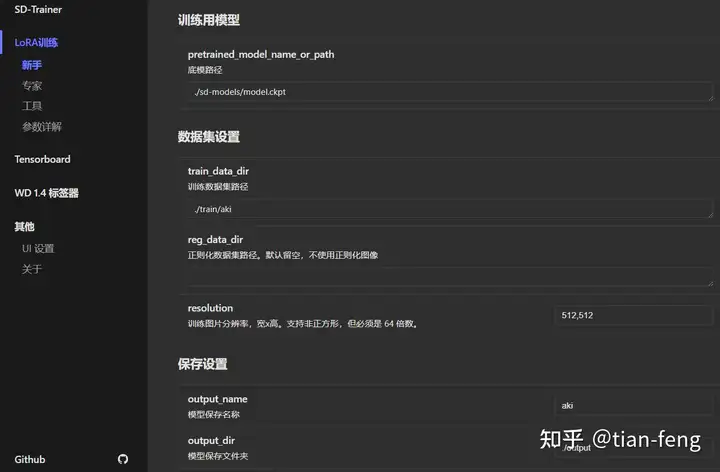
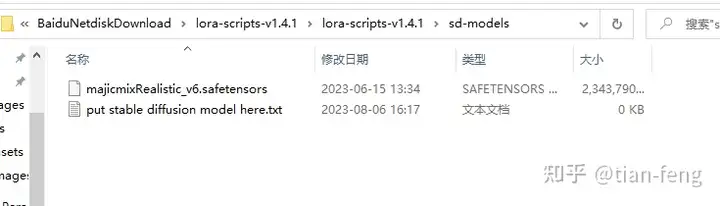
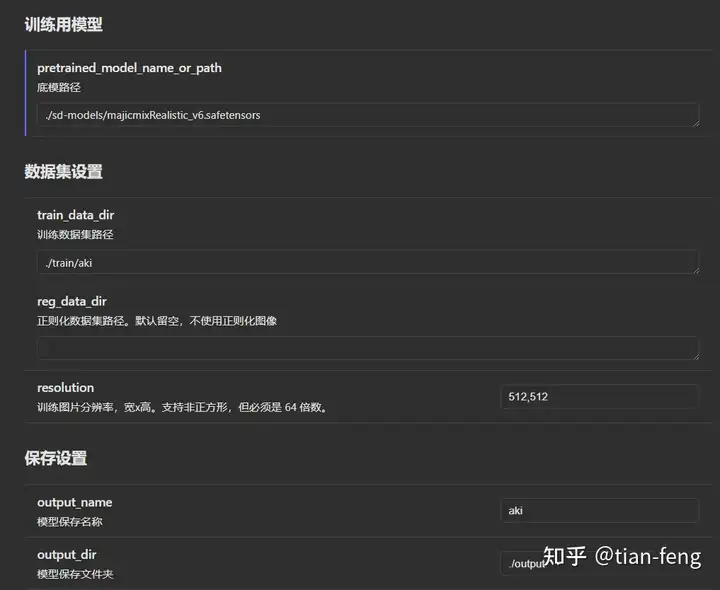
训练准备首页设置我们需要准备使用的基础模型(大模型),和我们的训练集图片。现在我以自己举例开始演示!
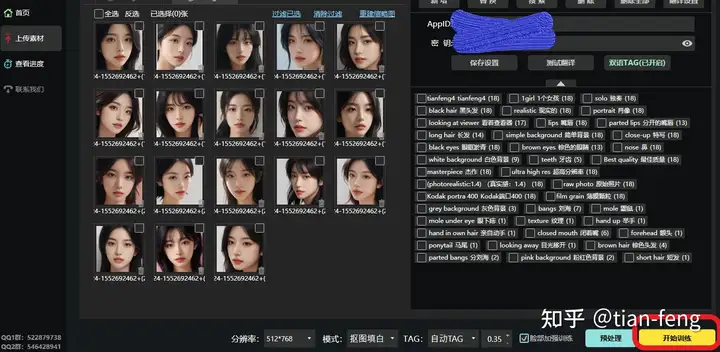
点击选择我们的大模型路径,召唤词可以自己命名一个,样张预览开启,就是训练的时候每50步会生成一张图查看训练效果。 好了,点击人物,确定到下一步! 上传素材
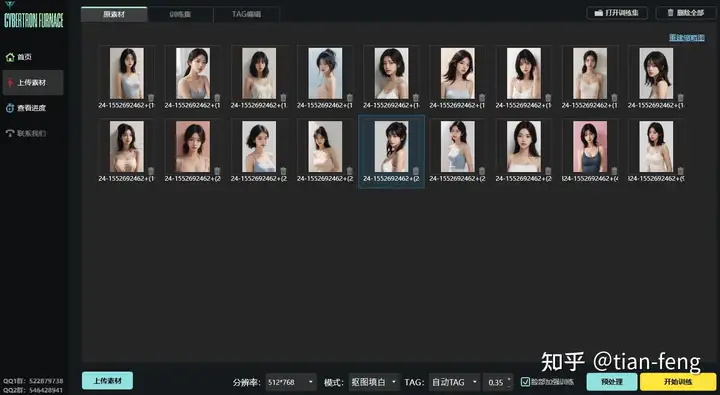
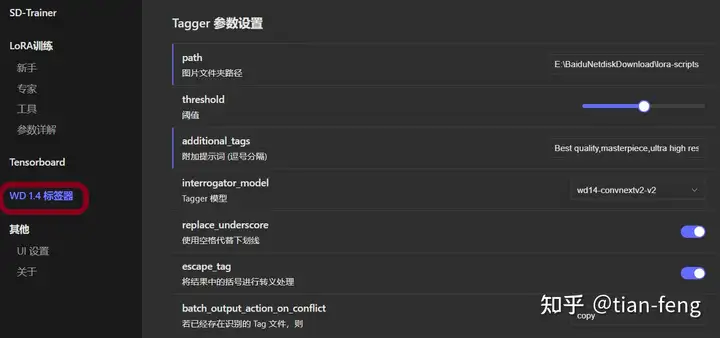
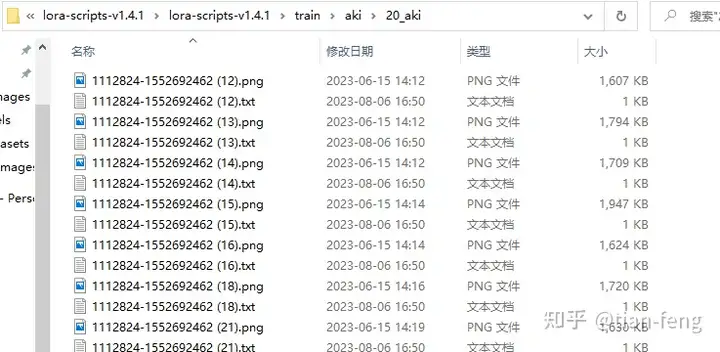
训练集最好准备50张图片,包含不同角度,你的训练集质感越高,你训练出来的效果也越好,可能几个epoch就能达到很好的效果,如果训练集模糊。质感差,100张图片,20个epoch效果也很差! 分辨率不用改,或者改成768x768, 模式选择抠图填白,就是去除背景,只保留人物做训练 TAG选择自动TAG,使用的是WD1.4TAG反推器 标签可信度阈值默认0.35,数值越小TAG越多,数值越大TAG越少,就是设置越小,反推生成TAG越多 如果训练脸部请勾选,最后点击预处理 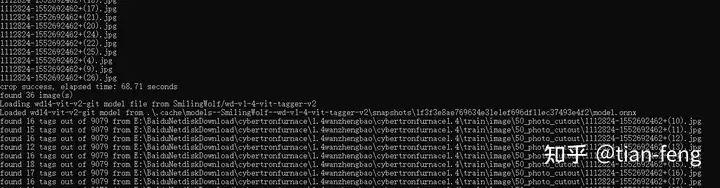
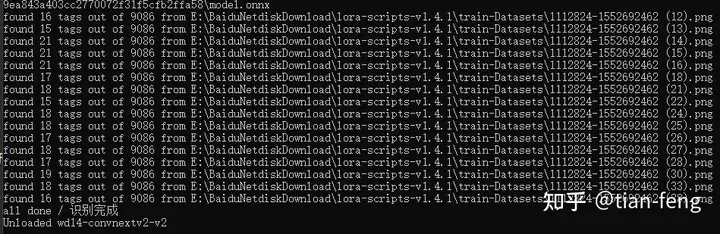
后台可以查看进度,一般是先抠图,后TAG反推。ok,抠图完成,脸部也单独提取出来了 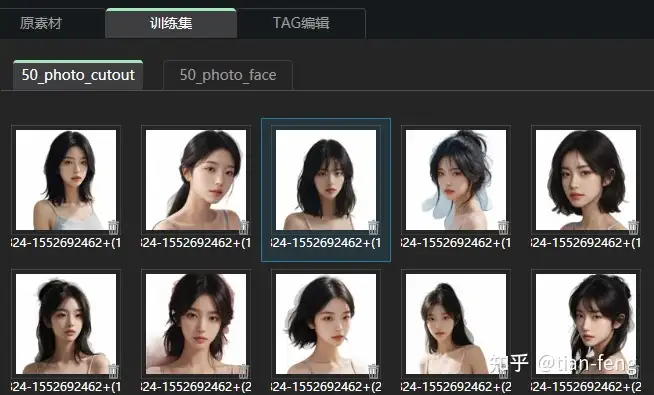
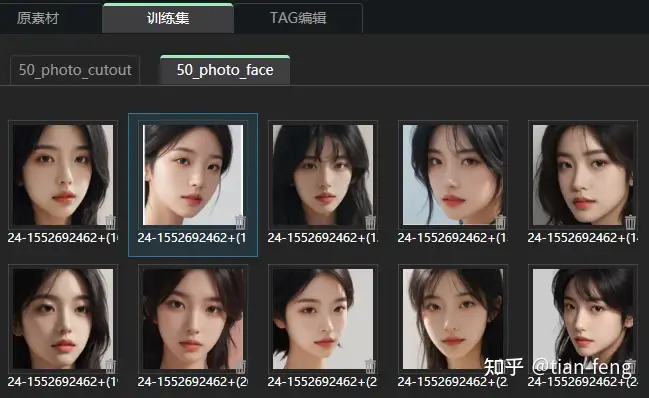
TAG反推也完成了,你还可以为每张图增加一些提示词,如光影,质感等词汇
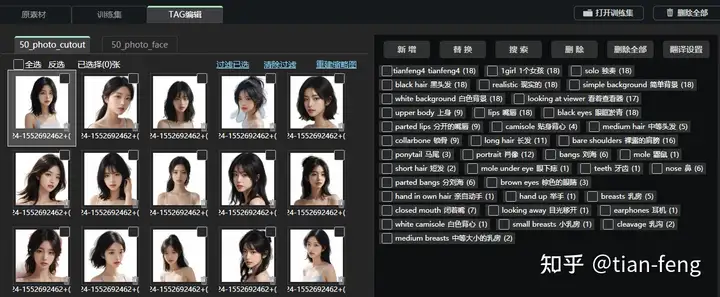
我这里整理一些,把这些TAG全部新增到每张图片,别忘了脸部也新增一下。 Best quality,masterpiece,ultra high res,(photorealistic:1.4),raw photo,Kodak portra 400,film grain,
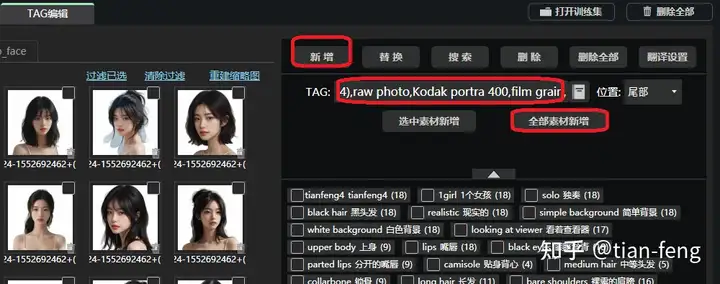
=====================================
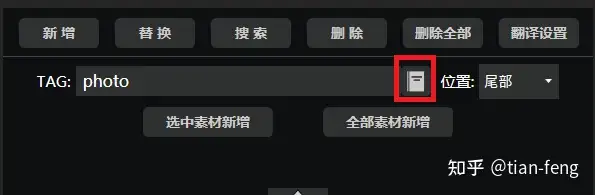
顺便推荐一个中文自动转英文的功能,打中文点击红框,自动转英文。需要的按我步骤操作一下,
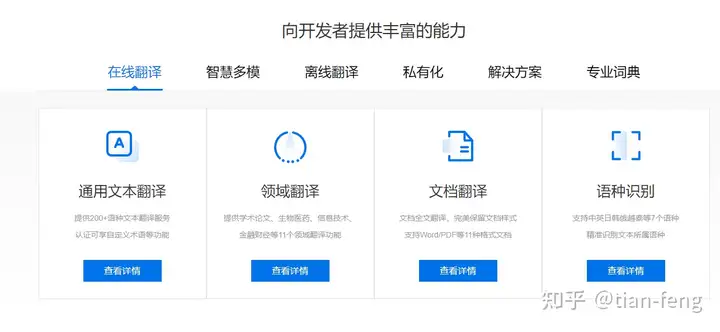
点击立即使用 
然后选择个人开发者,填写一些个人信息,然后选择高级版,实名认证一些,图片就不放了,因为我弄过了,就是按照流程来,很简单,之后点击界面最上面的管理控制台选项,点击开通 
然后选择通用文本翻译,开通高级版,最后一步填写应用名称就行,其他不管,提交申请就完了。
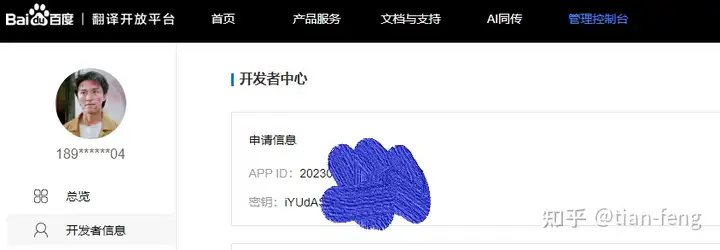
把APPID和密钥填入开启就完成了。
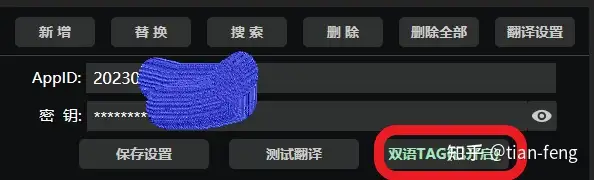
=====================================================
查看进度
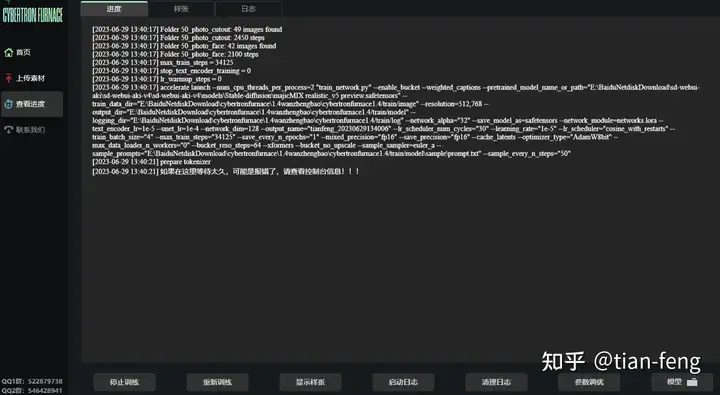
先别点击开始训练,查看进度界面,点击参数调优
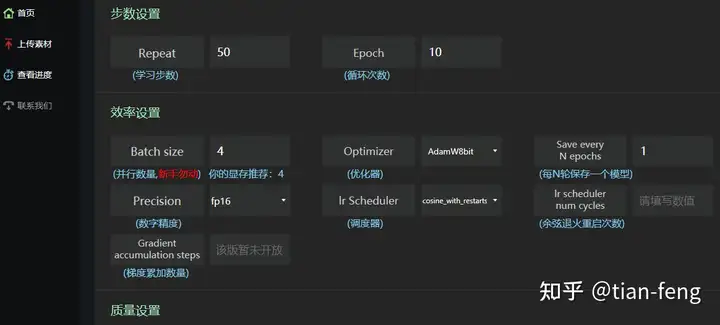
学习步数默认50步,,epoch可以选择20,batch size可以选择4,优化器Adam,没训练一个epoch保存一次权重(模型),Precision选择半精度(负2的15次方到2的15次方之间的数),调度器默认,余弦退火就是学习率曲线类似余弦函数一样,先增大后减小,重启次数应该就是周期数,暂时默认不填。
总步数就是50x50x20/4=12500步,假如50张图片,如果加强脸部训练,步数翻倍。
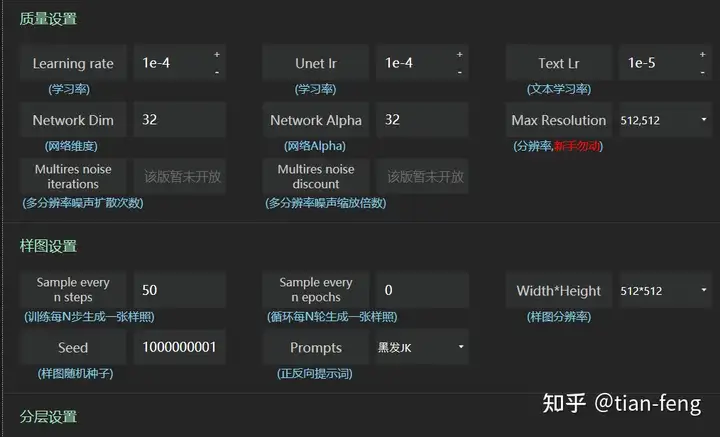
我只讲一下关键参数,其他默认,学习率默认,网络维度选128,效果比较好,训练出来的lora模型文件大小144M,这也是为什么市面上不同的lora大小模型,网络维度128,64,32,分别对应144M,72M,36M网络Alpha需要调成和网络维度一样,或者一半。 如网络维度128,网络Alpha128或64。(写实或是产品类的,希望精细度高的建议用128)
样图分辨率设置成和前面图片预处理一样,如果是768x768,那么这里也改成768x768。如果爆显存就默认别改了。 样图设置可以随意不影响,可以每50步生成一次,第二个就不用改了,基本默认就行,种子随意都行,样本生成的提示词选一个。
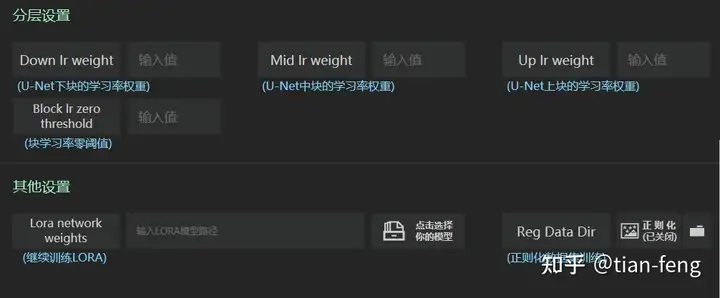
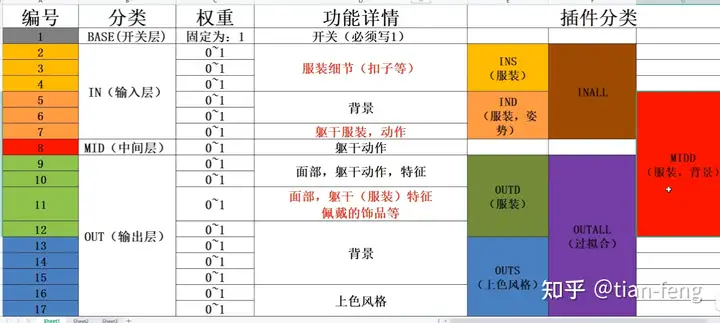
分层训练,可以查看下图,仅帮助理解,因为lora仅仅是训练一部分网络架构,不是全部unet,unet网络就是一个u型网络架构,先进行下采样在进行上采样,中间一层就是中间层。之前写过stable diffusion原理时候讲过Unet,有兴趣看看。链接
如果没有特殊需求分层设置先默认不填,其他设置中可以加载预训练模型,如果你上次训练了一个模型没跑完,只训练8个epoch,效果不好,可以加载模型路径继续训练节省时间。正则化就是防止过拟合,如果想要开启正则化,点击开启。然后把你的图片放入正则化文件夹就行。 参数调整完毕!!回到界面,点击开始训练!!!
之后就开始训练了,耐心等待,可以查看日志,模型保存的路径点击模型即可,
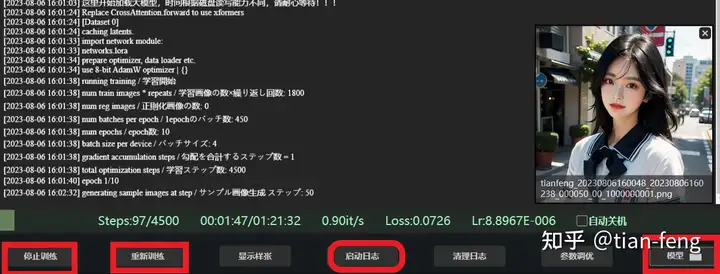
我们所有的训练数据都在这,包括训练集,日志,模型,正则化目录
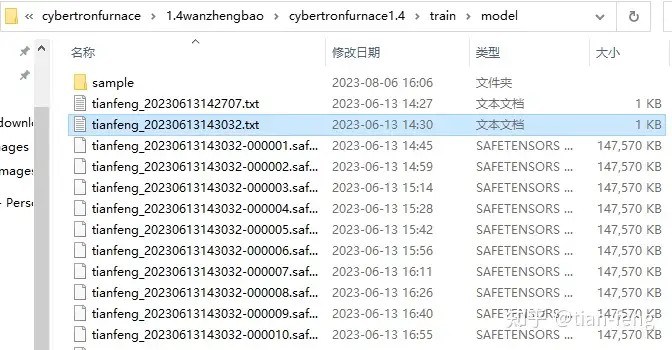
可以看到,样图,训练的参数配置文件,以及每个epoch的模型都保存在这,建议分别在前中后选取模型测试效果,epoch少的不一定差。对了,文件名可以改的,不影响。
到此,赛比丹炉介绍完毕了!!!应该很详细了,点个赞给博主提提神把,下面开始秋叶大佬的!
|  |Archiver|手机版|小黑屋|吹友吧
( 京ICP备05078561号 )
|Archiver|手机版|小黑屋|吹友吧
( 京ICP备05078561号 )


 狗仔卡
狗仔卡 发表于 2024-1-5 10:32
发表于 2024-1-5 10:32
 提升卡
提升卡 变色卡
变色卡 显身卡
显身卡